Software engineering
Understanding Monomorphism to Improve Your JS Performance up to 60x



I tweeted about polymorphism and a lot of you were asking for a more in-depth dive into it. So let’s get to it.
Virtual Machine
The most important thing to understand is the concept of a virtual machine (VM). The word virtual implies that the “machine” that the program is executing on is not physical but rather emulated. This means that the physical CPU execution model is too limited to execute a high-level language such as JavaScript with complex constructs such as modules, closures, and objects.
There are two ways to deal with that. A compiler that maps the high-level concepts, such as objects/closures/etc., into low-level concepts that the CPU can execute: memory access and subroutines. If the translation is done ahead of time, we call it a compiler. If the translation happens as the application runs, we call it a JITing (JIT means Just In Time and refers to Just-In-Time compilation), and we call it the environment in which we run a virtual machine.
Classes
There are many things that a VM needs to map to a physical CPU, but in this post, we are going to talk about objects/classes. Going forward, I will just refer to them as classes to differentiate them from arrays (arrays are also objects), which are treated differently. So an object literal is a class for the purpose of this discussion.
Even though we don’t think of it as a class, the above is stored as a class inside of a JavaScript VM. A key concept behind a class is that you can access its content through property accesses.
CPUs don’t understand classes
The thing to understand is that physical CPUs don’t have a concept of a class. A class is a higher-level construct that a VM needs to translate into a low-level concept so a CPU can understand.
CPUs only understand reading memory at an address or reading memory at an offset from an address. This is not quite the same as an array, but an array is a very good analogue. So to explain what is going on CPU level, we will treat memory access as array access.
VMs downlevel
The purpose of a VM is to downlevel the classes concept into an array access in such a way that it behaves “as if” the CPUs understood classes.
Property access
The above described how objects are stored as arrays, now let’s talk about property access. The job of the VM is to translate the properties into array access, and it does this like so:
Notice that the VM first reads the ClassShape from location 0 and then finds the specific property through indexOf(). The resulting index is incremented +1 to correct for the ClassShape, which is then used to read the actual value. (Similar process can be used for writing.)

NOTE: The actual implementation of indexOf() is a bit more complicated and is O(1) rather than O(n) as the above code would suggest, but in an effort to keep the above code straightforward, it has been greatly simplified.
Getting the property index is slow
Invoking indexOf() is in the hot path as well as slow. (Hot path refers to a part of a program that is used frequently or is critical). Strongly typed languages can do the property name to index transformation at compile time, but structurally-typed (duck-typed) languages can’t, so it has to be done at runtime.
If you remember, when V8 first came out in 2008, it was significantly faster than other JavaScript engines. Part of this is that V8 introduced an inline cache to the JavaScript world (inline caching has been used in JVM and Smalltalk for ages, so it was not an innovation).
Inline-cache
V8 uses JIT. This means that V8 executes JavaScript in normal mode, and while that happens, it collects information on how the application runs. Once the function is deemed in a hot path, it is recompiled with a set of assumptions gathered during the normal execution mode. These assumptions allow the JITter to make shortcuts that greatly improve performance.
While executing in normal mode:
What the normal execution learns is that the shape of the obj[0] is always vmShape1 so it can JIT the output to a much more efficient format:
This one trick can increase property read 60x! That is a huge improvement in performance!
Multiple shapes
Alas, the real world is a bit more complicated. The above code runs fast only if the shape of the objects feed to the map() function are always the same. What happens if there are different object shapes?
In this case, the translation is a bit more complicated:
Most VMs are willing to inline up to 4 different shapes before they fall back into the slow path.
Monomorphism, Polymorphism, and Megamorphism
VMs have names for this behavior. These are monomorphic, polymorphic, and megamorphic property read. So let’s spend some more time defining this.
- Monomorphic: If a property read always gets the same class shape, then that property read site is called monomorphic.
- Polymorphic: If the property read gets few (four or fewer) different class shapes and can be handled by the inline cache, the property read site is called polymorphic.
- Megamorphic: If the property read site sees more than four different class shapes, it is known as Megamorphic and is always handled by the slow path.
Megamorphic cache
There is a second-level cache that VMs employ. The indexOf() method is a crude approximation of what is happening in the VM. The actual method implementation is O(1), not O(n), as the indexOf() may suggest.
The indexOf() method also uses a cache that keeps track of the last N property-ClassShape reads (or writes). In V8, the N is 1024, so if calling indexOf() on a property-ClassShape, that was recently seen, the indexOf() can respond much faster than if it is called on a property-ClassShape that has not been seen recently.
Real-world numbers
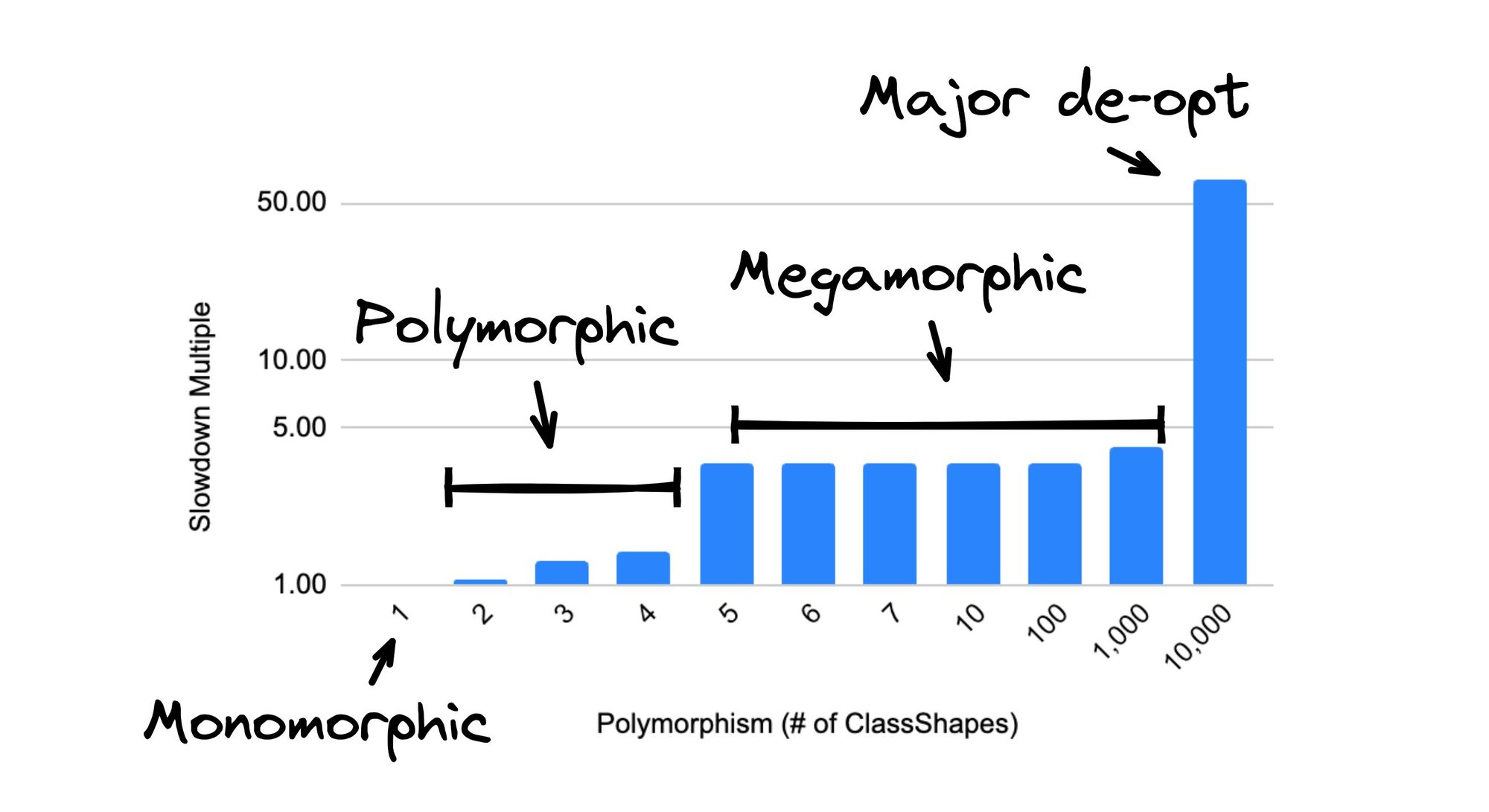
So how much of a difference does all of this make? Quite a lot, actually! Check out this benchmark and the results.

We assume that the monomorphic case is of unit cost 1. Notice that as the degree of polymorphism increases from 1-4, the inline cache can keep up, and the response is pretty good, with the 4-way inline cache being only 40% slower than the 1-way inline cache (the ideal case). After 4-way, the VM gives up and reverts to indexOf().
However, indexOf() has a megamorphic cache, so while it is about 3.5x slower than a 1-way cache, it still performs pretty well. But notice that at 1000 different shapes, the performance starts to fall off. That is because the megamorphic cache overflows, and we revert to the worst-case scenario. The worst-case scenario is 60x slower than the megamorphic case. That is significant!
Microbenchmarks
People love to write microbenchmarks to prove their point. But beware, a lot of microbenchmarks fall victim to not being reflective of real-world use cases. Most of these fail because the number of class shapes fed through the function does not reflect real-world use cases.
This means that inline cache will kick in and make the code appear way faster than in real-world cases. And even if we feed more shapes, it is unlikely that we will overflow the megamorphic cache in the micro-benchmark.
Conclusion
CPUs don’t understand many of the concepts we take for granted in our high-level programming languages. The job of the VM is to emulate the high-level concepts from the low-level primitives which the CPUs understand.
Many of these emulations are expensive, so VMs employ tricks that speed up the execution of the code. Understanding these tricks can help you better understand when code would be fast and when it could be slow.
The biggest caution is accepting micro-benchmarks at face value because they often show performance that disappears on more realistic real-world scenarios with more class shapes showing up.
Share